SplatGPT: Set-Based Deep Learning for Splatoon Gear Completion
Intro
At first glance, optimizing gear loadouts in competitive games seems straightforward: identify the best combinations of abilities for each situation. However, when these systems allow for complex stacking mechanics and context-dependent effectiveness, the problem becomes remarkably challenging for traditional machine learning approaches. Nintendo’s Splatoon 3 presents an especially fascinating case study, where the interaction between gear abilities, weapon choice, and player strategy creates an optimization problem that reveals fundamental limitations in how we typically approach set-based prediction tasks.
The Deceptive Complexity of Loadout Systems
Imagine trying to build a recommender system for the optimal gear setup for a player. A naïve approach may suggest looking at what high-level players use and replicating their choices. Indeed, this is what multiple websites have attempted to do. However, this runs into problems. How do you account for multimodality? Can you still build proper recommendations for highly unpopular weapons? How do we distinguish between intentional choices and noise?
The Splatoon Gear System
Splatoon 3 is Nintendo’s wildly successful 2022 team-based competitive shooter where players battle as squid-kids. Before even entering a match, players face a strategic decision that affects how they play: they must select a gear loadout that complements their weapon choice and personal playstyle.
You can think of Splatoon’s gear system as the outfit your character is going to wear, and it consists of three distinct types: headgear, clothing, and shoes. Each piece of gear contains one primary (main) ability slot, three secondary (sub) ability slots, and a set of four unique main-slot-only abilities specific to that gear type. For example, the ability Comeback is only found on headgear.
Weapons and Gear
Understanding weapon mechanics is crucial for gear optimization because different weapons demand different ability configurations. Weapons as they’re set up in Splatoon 3 follow a hierarchical structure:
- Weapon Class (e.g. Shooter, Roller, Charger)
- Defines basic movement, attack patterns, and controls; archetype-level
- Specific Weapon (e.g. Splattershot, Carbon Roller, E-liter 4K)
- Determines precise statistics and handling
- Weapon Kit (e.g. Splattershot vs Tentatek Splattershot)
- Provides specific sub-weapon and special weapon combination
- Influences optimal gear choices even with the same specific weapon
Ability Stacking
The complexity of gear optimization emerges from the ability stacking mechanics:
- Standard abilities can be placed in any slot
- Primary slot abilities have a weight of 10
- Secondary slot abilities have a weight of 3
- Each ability follows a unique, non-linear effectiveness curve:
- Some abilities provide significant benefits from the minimum possible investment ("utility subs")
- Others require substantial investment to reach meaningful effectiveness.
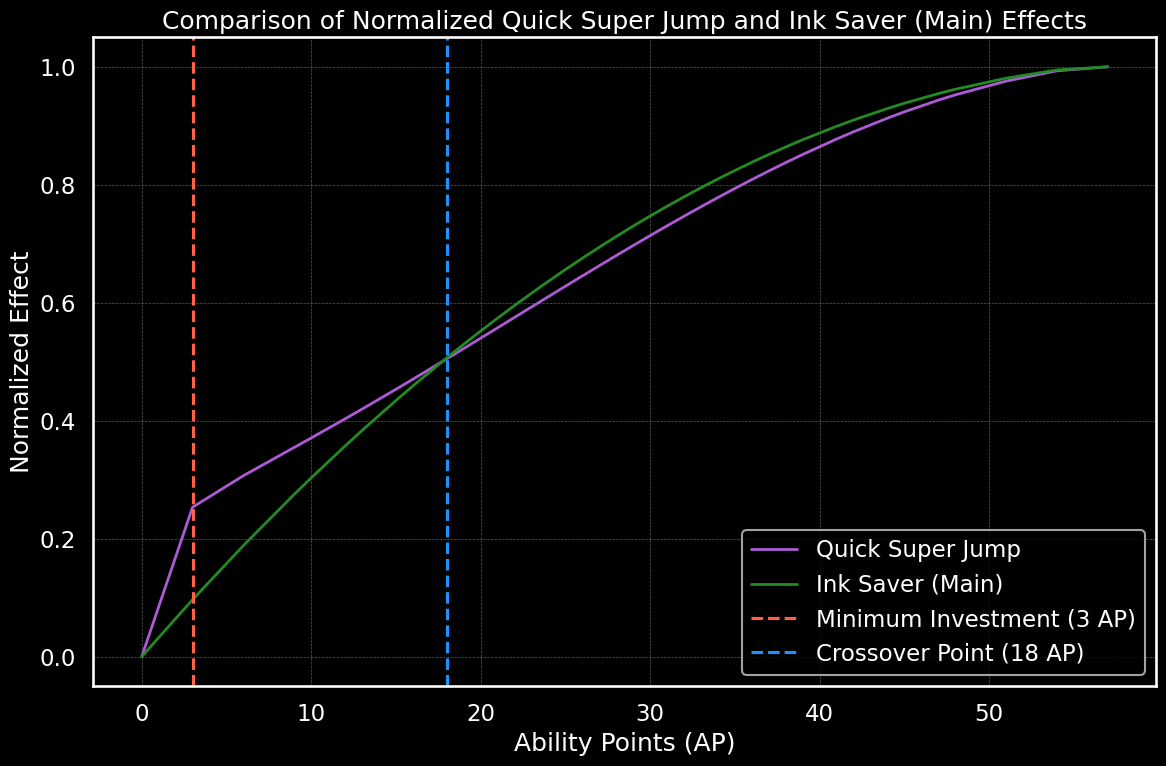
This creates an optimization problem where the value of each ability slot depends on:
- The ability itself
- Total investment in that ability across all gear
- Synergies with other equipped abilities
- Synergies with selected weapon
- Playstyle considerations
Data Challenges
As yet another wrinkle, the gear system in Splatoon 3 introduces several layers of noise into any data gathered:
-
Random Ability Assignment: Secondary slots are initially filled randomly based on the gear's brand. Each brand has its own probability distribution as to how those secondary slots are filled.
-
Optimizing is Expensive: While players are able to change abilities of their piece of gear, it requires significant time investment. As a result, observations may be an incomplete optimization. Additionally, players will reuse gear optimal for one weapon across multiple weapon setups.
-
Player Expertise Distribution: Not all players fully understand the complex mechanics behind ability stacking. Some choices might reflect a poor understanding of the game rather than a well-understood strategic decision. Some players might simply value aesthetics, regardless of the abilities.
-
Build Multimodality: Many weapons have multiple viable optimal builds, while others have a single niche. Meta shifts can also change a weapon's niche, invalidating previously optimal gear configurations.
More Context Needed
What makes this system particularly challenging for traditional machine learning approaches is that noise in the data cannot be identified without understanding the full context. A single Quick Super Jump ability in a secondary slot might be:
- An optimal choice for the current weapon
- A random ability from initial brand probabilities that hasn't been changed
- Part of optimal gear for one weapon, used for another weapon
The interpretation depends entirely on:
- The weapon being used
- Other abilities present in the build
- The current competitive meta
This contextual dependency means we can't simply treat unexpected configurations as noise to be filtered out – they might represent valid strategic choices that only make sense when considering the full picture. Traditional approaches to handling noise rely on the assumption that noise can be identified through statistical patterns or outlier detection. However, in the Splatoon 3 gear system, what looks like noise in one context may, in fact, be raw signal in another.
Requirements for High Quality Recommendations
Given all of these interacting complexities that compound upon each other, any model attempting to achieve a high performance on gear prediction must simultaneously satisfy multiple requirements:
1. Set Processing
- Must handle unordered collections of abilities
- Needs to maintain identical predictions regardless of ability slot ordering
- Should process all gear pieces together as a complete loadout
2. Nonlinear Interactions
- Must capture complex stacking effects between abilities
- Should implicitly understand ability breakpoints and effectiveness curves
- Needs to model synergies between different abilities
3. Contextual Understanding
- Must process weapon information alongside gear choices
- Should recognize valid variants in builds for each weapon
- Needs to distinguish between intentional choices and noise based on context
4. Multimodal Predictions
- Must be capable of suggesting multiple valid configurations
- Should avoid collapsing to a single recommendation regardless of input
These requirements suggest the need for an architecture that can process sets while maintaining awareness of the relationship between all elements and their context. Traditional sequence models and standard neural networks are fundamentally ill-suited for this task. Given these stringent requirements, a novel approach is needed. One that can handle the set-based nature of the problem while capturing intricate interactions.
Attention
To tackle the complexities of Splatoon's gear optimization, I drew inspiration from the attention mechanisms in transformer models. Attention inherently provides a way to incorporate context by allowing each element in a sequence to interact with every other element. Crucially, when positional embeddings are omitted, attention becomes permutation invariant—making it ideal for processing sets where order doesn't matter.
This property aligns perfectly with our challenge. In the gear system, the effectiveness of an ability depends not just on its presence but also on its interaction with other abilities and the chosen weapon. By using attention mechanisms, we can model these interactions holistically, ensuring that each ability's impact is considered in the context of the entire set.
A Two-Stage Approach
Realizing that attention mechanisms could address our needs, I embraced the set-based nature of the problem and modeled it as a multilabel classification task. Here's how:
1. Discretization and Tokenization: Standard abilities are discretized into buckets based on their stacking weights and effectiveness, transforming continuous ability values into categorical tokens. Main-slot-only abilities are straightforward to tokenize because they are tied to a single gear type and cannot be stacked.
- However, discretization introduces a loss of exact information. To construct a valid gear set that adheres to game constraints (like slot limitations, mutual exclusivity between pairs of abilities, etc.), we need a method to translate these probabilities into a feasible loadout.
2. Probability Prediction: A deep learning model predicts the probability of each discretized ability token as being part of the optimal gear set. By treating these tokens as labels, we can handle multiple abilities simultaneously, reflecting the multilabel nature of gear configurations.
3. Gear Set Construction: Turning the probabilities into a gear build has multiple viable approaches. Instead of relying solely on the model's initial output, we employ a deterministic algorithm; specifically, beam search. This algorithm iteratively builds gear sets by selecting combinations of abilities that maximize the overall predicted probability while satisfying all constraints. It effectively bridges the gap between probabilistic predictions and practical applications. While the specifics of this algorithm are beyond the scope of this post, it serves as a crucial bridge between probabilistic predictions and practical gear set construction.
By splitting the problem into these two components, we leverage the strengths of deep learning in modeling complex, context-dependent interactions and use algorithmic strategies to ensure valid, optimized outputs.
Introducing SplatGPT
By integrating these strategies, I developed SplatGPT, a model tailored for the Splatoon gear optimization challenge. SplatGPT enhances the Set Transformer architecture with elements inspired by GPT-2, specifically designed to handle the unique aspects of this problem.
-
Embedding Layer: The model starts by converting discretized ability tokens and weapon IDs into embeddings. By adding the weapon embeddings to the ability embeddings, we provide contextual information that allows the model to understand how weapon choices influence ability effectiveness while retaining the ability for the model to transfer synergies from more popular weapons to less popular weapons.
-
SetTransformer Layers: SplatGPT employs multiple layers of what I call the SetTransformerLayer. Each layer processes the input set through a Set Transformer module which, due to its design, maintains permutation invariance. This ensures the model's predictions are based solely on the combination of ability tokens and not their order.
- Cross-Attention Mechanism: Within each layer, the output of the Set Transformer serves as the key and value in a cross-attention mechanism, with the original input as the query. Using the original input as the query allows the model to reference the initial state of the abilities, ensuring that the refined understanding doesn't drift from the original data while retaining the input sequence length. This setup allows the model to refine its understanding by focusing on relevant interactions between abilities.
- Feedforward: Each SetTransformerLayer ends with a feedforward layer that increases dimensionality, passes the input through an activation function (in this case GeLU, or Gaussian Error Linear Unit, which helps model complex patterns), and returns dimensionality to what it was before.
- Residual Connections: Through the use of residual connections, the layers build higher-order relationships that capture complex interactions between abilities and weapons. These connections enable what's sometimes referred to as "virtual attention," enhancing the model's capacity to learn intricate patterns.
-
Masked Mean Layer: To aggregate information across the set and ensure permutation invariance, the inputs pass through a masked mean pooling layer. This mechanism averages the embeddings while accounting for variable input lengths, effectively summarizing the set without imposing any order.
-
Output Layer: The final output first is projected to the size of the dictionary before it passes through a sigmoid activation function, generating probabilities for each ability token. This framing as a multilabel classification problem enables the model to predict multiple abilities simultaneously, capturing the multimodal nature of optimal gear configurations.
SplatGPT effectively models the intricate, nonlinear relationships within the gear system, accounting for ability stacking, weapon synergy, and contextual dependencies. By integrating attention mechanisms and set-based processing, it overcomes the limitations of traditional models, providing accurate and practical gear recommendations.
Cross-Attention Mechanism in SplatGPT
The key breakthrough that allowed me to create SplatGPT by putting in a Set Transformer into a GPT-2-like architecture was cross-attention. Here's a more detailed explanation:
Maintaining Sequence Length
The Set Transformer module inherently includes a pooling operation that reduces the sequence length by summarizing the input into a condensed representation. While this is beneficial for capturing global set information with permutational invariance, it poses a challenge when integrating to the residual stream, as the sequence length must remain consistent across every connection back into the stream in order to work effectively.
To address this, I introduced a cross-attention mechanism that maintains the original sequence length. Here's how it works:
-
Cross-Attention Setup: The output of the Set Transformer (the pooled, set-level representation) serves as the key and value, while the original input sequence acts as the query in the cross-attention mechanism.
-
Functionality: This setup allows each position in the original sequence to attend to the set-level context captured by the Set Transformer. Essentially, it broadcasts the set-level information back to each individual token while preserving the sequence length.
Adding Context
This process effectively distributes the aggregated set-level information back to each individual token, enriching their representation. In essence, each token now:
-
Holds Context: Each token incorporates some information about its role within the entire gear set and its interaction with other abilities in the build.
-
Captures Complex Relationships: With each additional SetTransformerLayer, the model refines these representations, enabling it to model increasingly complex interactions between abilities.
-
Benefits from Deeper Layers: The stacking of layers allows the model to build upon previous representations. Since each SetTransformerLayer is part of the residual stream, the higher-order relationships that can be captured as a result of preserving sequence length are much more than the sum of their parts. For more information on this, check out A Mathematical Framework for Transformer Circuits by Anthropic.
Why It Matters
-
Context-Dependent Abilities: The effectiveness of an ability often depends on other abilities equipped and the chosen weapon.
-
Nonlinear Synergies: Certain ability clusters behave differently based on the surrounding context. While Comeback and Quick Respawn with 15 Ability Points (AP) have high amounts of synergy, if the input tokens include Quick Respawn with 40 Ability Points, the amount of synergy between Comeback and Quick Respawn 15 is much lower.
-
Comprehensive Modeling: By enriching each token with the set-level context, the model can make more informed predictions about which abilities will optimize performance.
Why Not Self-Attention?
As mentioned above, attention is set-based in nature and needs to be provided positional embeddings for sequence-to-sequence tasks. So why not use self-attention? Why use a Set Transformer at all with Cross-Attention?
The primary reason is because self-attention works as pairwise relationships. Though the residual stream allows significantly more complex interactions over multiple layers of self-attention, we are still dealing with sets. That is, we have to deal with \( 2^n \) possibilities where \( n \) is the number of tokens in our vocabulary. We’d need many layers of self-attention to replicate what we can get with a few layers of cross-attention with the set transformer output.
Results
Evaluation
Evaluating a gear optimization model for Splatoon 3 presents a unique challenge. The true test of a build’s effectiveness can only be measured across hundreds of games with multiple players – a scale of testing that proves infeasible given Nintendo’s locked-down API and the demographic challenges of convincing younger players to systematically track their games.
Where are the Standard Metrics?
Traditional evaluation metrics would require large-scale user testing under controlled conditions. Since there is no direct efficacy score that we can extract from just the gear that the model produces, we would need to rely on players testing these out and aggregating results over dozens of matches per build in order to properly evaluate. Unfortunately, there are a few issues here. First, Splatoon 3's closed API and Nintendo's strict data policies make gathering such data nearly impossible. Second, coordinating players to pull this off would itself be a herculean logistical feat. Finally, meta shifts can quickly invalidate any static benchmark. As a result, we have to rely on qualitative feedback from top competitive players. While not the usual setup, the anecdotal evidence so far has been quite promising and has revealed both strengths and limitations of the model.
Initial Validation
Initial validation came from my own experience as a player ranked in the top 10,000 globally. Once the model began consistently surpassing my build optimization abilities, I sought more rigorous validation from top competitive players. These experts were asked to select random weapons they felt comfortable with and provide partial builds with varying levels of completion – ranging from nearly complete setups to just weapon selection. This tested the model’s ability to both complete existing builds and construct entirely new ones from minimal input.
Surprising Results
The response from top players was unanimously positive, with reactions ranging from impressed surprise to outright disbelief. The most compelling example came when the model perfectly reconstructed a top player’s build for an extremely unpopular weapon, working from just a half-completed build – and did so without having seen that specific configuration or similar builds in its training data. This demonstrated not just pattern matching, but a genuine understanding of gear optimization principles.
However, the model isn’t without limitations. Weapons with minimal representation in the dataset, particularly when combined with unpopular abilities, can produce suboptimal results. While this seems unavoidable given the current dataset constraints, it’s a clear area for future improvement.
Production Deployment
Perhaps the most meaningful validation is that this isn’t just a proof of concept – the model is already in production, actively helping players optimize their gear loadouts. It demonstrates that achieving superhuman performance isn’t necessary to provide real value to the community. Like a solid NBA bench player, it consistently performs at a professional level while maintaining room for growth. Additionally, an API endpoint was created to take player feedback on the autocompleted build. This will be used with RLHF or DPO to improve future builds.
Training Dataset
The primary dataset was sourced from stat.ink, a community platform where players upload their match data using third-party tools. While the platform provides anonymized data with identifiable information stripped, this presents potential sampling biases from the site's users being overrepresented. Several preprocessing steps were necessary to ensure data quality and manage potential biases.
Player-Level Bias Correction
- Limited entries to 50 per likely-player through a discriminator (not an identifier) created via side-channel analysis
- While imperfect, this is the best available compensation for sampling bias within the dataset constraints
Performance-Based Filtering
- Enforced a minimum 3:2 win-loss ratio on a per-weapon basis
- This intentionally introduces a bias against losing configurations
- Less effective builds or less skilled players are more likely to produce losses
Temporal Filtering
- Post-Update Periods:
- Dropped two weeks of data after new weapon introductions
- Dropped one week of data after balance patches
- Players experiment heavily during these periods, leading to unstable data quality
- Historical Data:
- Progressively dropped older data
- Accounts for meta shifts and evolution of optimal strategies
- Helps ensure model reflects current game state
Completeness
- Dropped all incomplete builds
- Ensures model trains on complete, valid configurations
Impact
The preprocessing decisions were carefully chosen using domain expertise to balance between availability and quality. The introduction of biases might seem counter-intuitive but serves to help the model produce optimal builds rather than replicating the dataset.
Training Process
Initial Success
The training process was surprisingly smooth. Even early runs produced builds that, while far from optimal, demonstrated a logical consistency that an experienced player could understand. This early success suggested that the architecture was well-suited for this problem space.
Data Preparation
The training approach drew inspiration from large language model techniques, specifically the sliding window method for next token prediction. Each build generated multiple training examples through progressive token dropping:
- Before training, select \( n \) for how many times each build will be used in the dataset.
- Generate a list of random numbers from 1 to \( k \) where \( k \) represents the sequence length, these will represent the number of ability tokens dropped for each training example.
- Initial attempts dropped largest ability buckets first
- Later switched to random drops, which improved learning of cross-bucket ability associations
- Padding tokens added to maintain consistent sequence length within batches
- Binary cross-entropy with logits selected as loss function
- Learning rate guided by validation set F-score after each epoch.
The development process utilized two distinct training scenarios:
- "Toy" models: Single RTX 2080Ti, 10-to-20-minute training runs for rapid iteration
- Production model: Single H100 GPU, 62-hour training period. While the training time could be optimized further, this was sufficient for production-quality results.
Emergent Behavior: The NULL Token
Possibly the most fascinating discovery emerged halfway through development with the introduction of a <NULL> token. Early experiments with <NULL> revealed two extremes:
- Including
<NULL>in all training data degraded overall build quality across the board - Sparse inclusion of
<NULL>tokens led to overfitting on builds lucky enough to get<NULL> - Anything in-between would lessen overfitting but also decrease overall build quality.
I made a completely baseless hypothesis: completely excluding the <NULL> token from training but including it as part of the vocabulary might make the model treat it as a root token for generating an optimal build given no input. This proved correct, with <NULL> consistently producing highly-effective weapon-specific builds – an emergent behavior that it was not explicitly trained for.
This unexpected success with the <NULL> token highlights that the model is actually developing optimization strategies and not simply regurgitating its training dataset. This is quite fascinating, as in a way the model is attempting to "reason" about what it should do given an unknown input.
Insights
To better understand how SplatGPT makes decisions, I developed a utility that applies the logit lens to each layer of the model. The process involves progressively truncating SetTransformerLayers until only the embeddings flow into the masked mean, followed by projection and activation. I then analyzed the results across a comprehensive set of inputs: every ability token paired with each weapon, at each layer depth. By tracking how probability distributions change between layers, we can effectively peek at the model’s “thought process” as it incorporates more contextual data and refines gear recommendations. See the appendix for excessive details on this.
Through this careful investigation using the logit lens, we can observe several patterns in how different types of ability tokens are processed:
- Role-defining abilities tend to show accurate predictions from early layers. Their inclusion in the input will shift the output distribution towards generally viable builds immediately.
- Multimodal abilities hedge significantly, with input probabilities clustered tightly around \( 0.5 \). As more context is added and it goes through more layers, these abilities will either have higher probabilities in the output distributions or go towards zero.
- Ubiquitous abilities that require contextual understanding show a mesa-shaped distribution, with most values between \( 0.4 \) and \( 0.6 \). This requires significantly more context, and the mesa-shape represents their high appearance rate in the training data.
<NULL>Token exhibits weapon-specific distribution patterns and undergoes more significant change in the first two layers compared to other tokens.
Conclusion
SplatGPT demonstrates that deep learning models based on LLM architectures can solve complex set-based optimization problems while capturing intricate domain constraints. Through careful architecture decisions, I created a model capable of understanding and leveraging the complex interactions between weapons, abilities, and playstyles in Splatoon 3.
The most fascinating aspects of this project were not the solutions we explicitly engineered but rather the behaviors that emerged. The <NULL> token’s ability to generate strong baseline builds despite never being trained on them suggests the model developed genuine optimization capabilities rather than simply memorizing common configurations. The fact that the model has reached such a high level of performance despite being trained on such a wide skillset is also very impressive and goes to show how we can extract the wisdom of the crowds through careful, thoughtful data preprocessing. Additionally, the logit lens analysis reveals how the model progressively refines its understanding of ability interactions across layers, with different patterns for role-defining, multimodal, and ubiquitous abilities.
While SplatGPT has proven effective enough to deploy in production, there’s still much to explore. Future work includes using sparse autoencoders to better understand the features being detected at each layer, expanding the training dataset to better handle rare weapon-ability combinations, and potentially applying similar architectures to optimization problems in other games. The model’s deployment was also equipped with a feedback endpoint tied to the API’s request id. This allows users to give both positive or negative feedback on builds. This is specifically to set up for the next stage of model improvement: having a dataset of judged model outputs in order to apply either RLHF or DPO. This should take the model from the current mid-level competitive player skill tier it is at and take it to top competitive.
The immediate success of the model suggests it is especially good at dealing with set completion tasks with a lot of contextual noise. While I can’t think of many processes that this would apply to outside of Splatoon 3, the existence of this solution will hopefully inspire other solutions the way LLMs and Set Transformers inspired me.
Appendix
Logit Lens Analysis
The figure below illustrates the distributions for nine different weapon/ability token input combinations. The first six are for the weapon Splatana Stamper as a case study for how the distribution is affected by the token selection as it is one of the weapons that is multimodal in nature. The last three are specifically chosen weapon/ability token pairs that illustrate some interesting quirks.
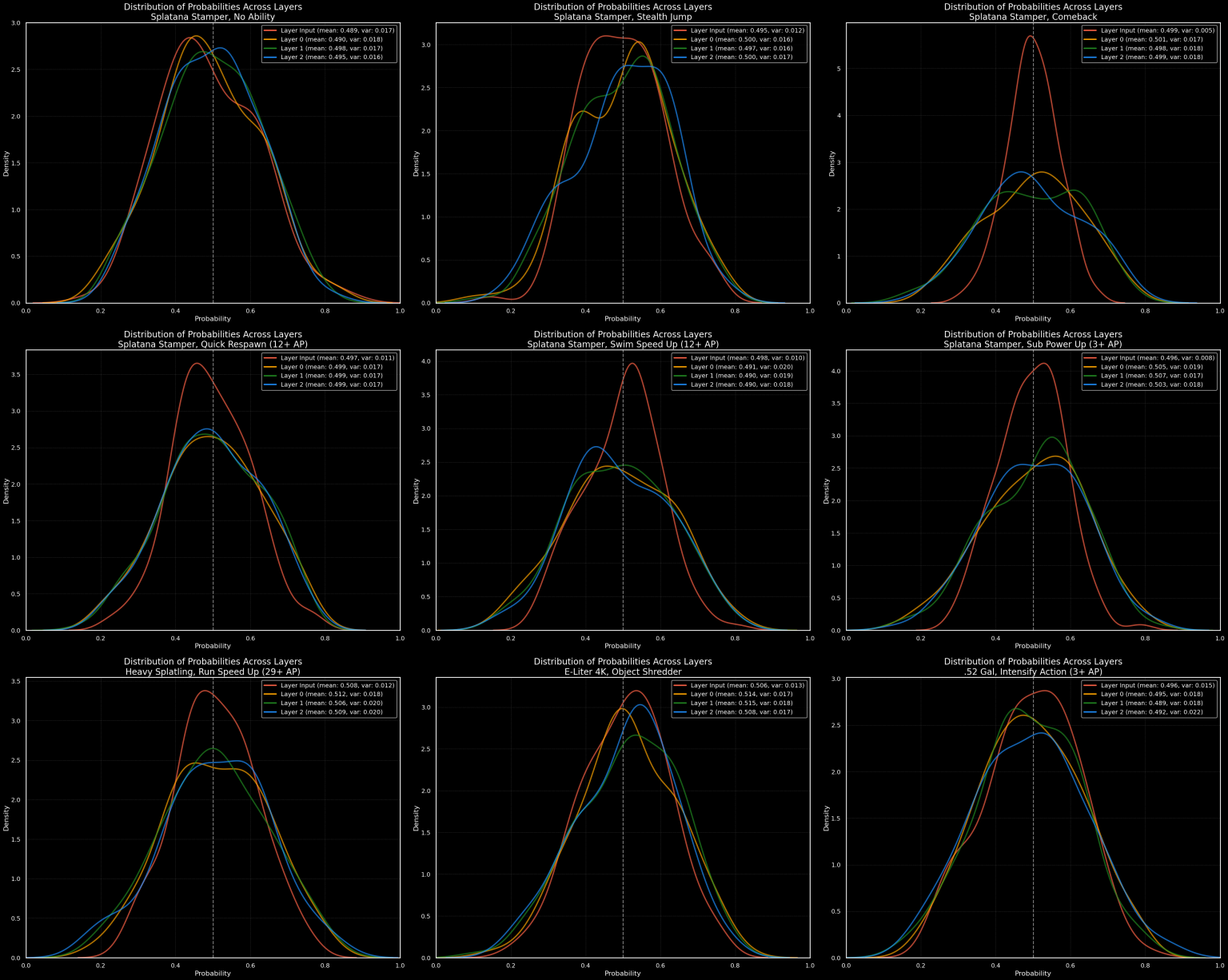
Shown above are a selection of nine logit lens distributions at different points of analysis, colored by their position on the visible spectrum:
- Input Layer -> Red
- Layer 0 -> Orange
- Layer 1 -> Green
- Layer 2 -> Blue
The first two rows are for the Splatana Stamper, a multimodal weapon with multiple viable builds. The selection of abilities to start with are from left to right then top to bottom: no ability, the single most commonplace ability, a highly commonplace ability for builds for this weapon, the two defining tokens for the different builds, and a minimal investment case that is signal here but is noise in almost any other context. The final row represents three selected weapons all with a representative of their builds. Below is a supplementary graph which has the differences between layers.
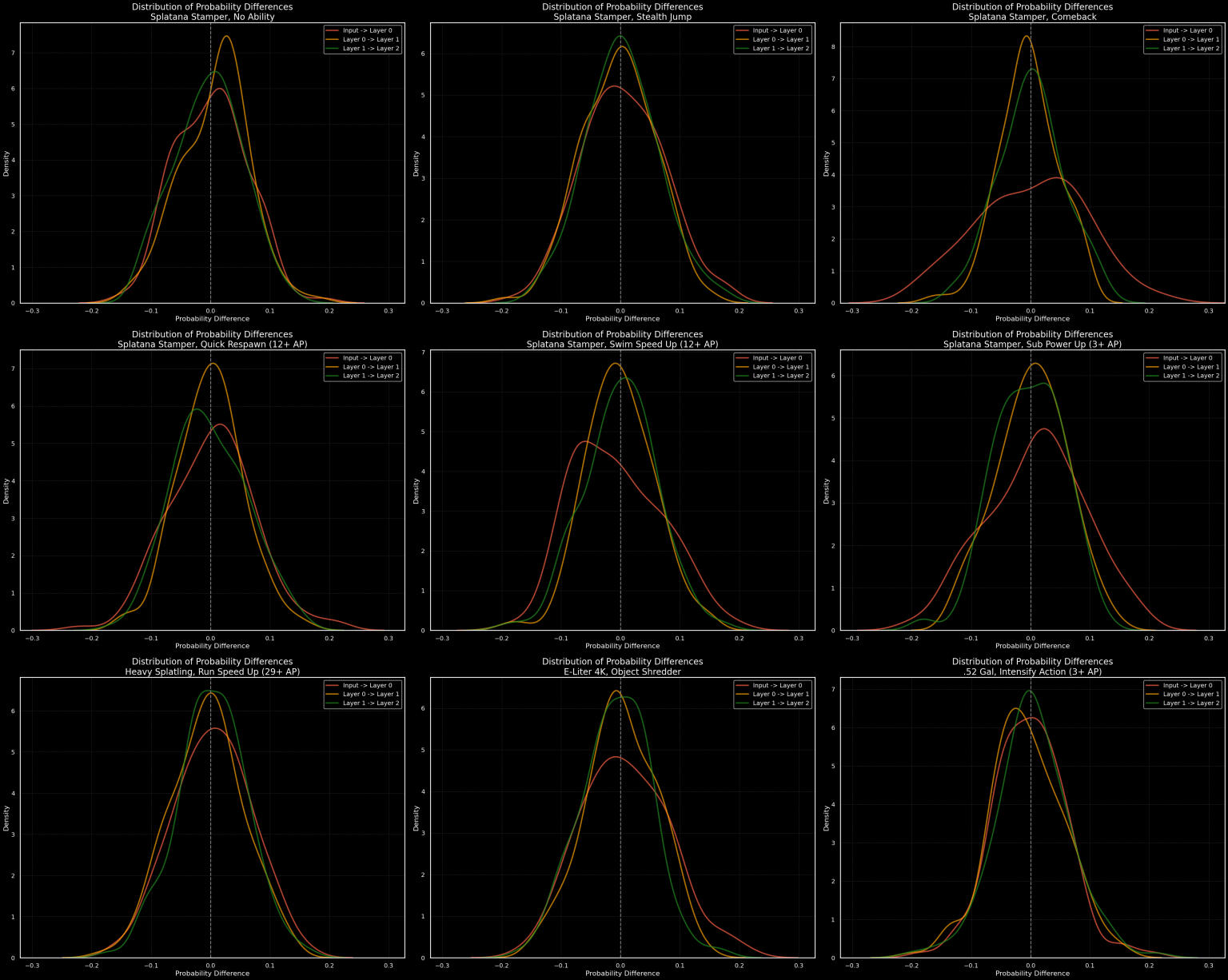
What we can tell from these differences between layers is that most of the feature selection is done by the first layer, with iterative refinements happening with each layer. What each feature actually is is not something I have looked into yet, though I will look into it via sparse autoencoders as detailed in this Anthropic paper