SplatGPT Part 2B: Training and Performance
Discover how SplatGPT was trained on curated data, overcame noise, and even predicted meta shifts to optimize competitive Splatoon 3 gear builds.
Recap
In Part 1, we explored the deceptive complexity of Splatoon 3's gear system and outlined three core requirements for any algorithmic approach to gear autocomplete: permutation invariance, non-linear capture, deep contextual understanding.
In Part 2A, we introduced SplatGPT, a novel deep learning model designed to tackle this challenge specifically. We detailed the architecture that powers it: a fusion of Set Transformers with a GPT-2-esque residual stack that worked in a discrete Token Space (Ability Point buckets). Gear is translated from Build Space (legal Splatoon builds) -> Token Space -> inference -> Build Space, letting the model reason over ability sets while still outputting legal Splatoon builds.
You Are What You Eat: Training Data
SplatGPT will only ever be as good as the matches it studies, but data for this purpose is difficult to source. Nintendo provides no public match API. The community instead reverse-engineered the companion app, which only exposes your most recent 50 games. Thankfully, the same community (I'm an active developer there!) built uploaders, and stat.ink now hosts 15 million player-submitted battles: manna from heaven for this project.
The catch? Despite stat.ink parsing and cleaning the data, it's still noisy. Some capture incomplete builds (builds that were literally missing abilities), others come from casual modes, and new-weapon patches destabilize the meta instantly. Finally, the classic long-tail: a few power users upload thousands of matches while most contribute only a handful, and raw statistics start to lie.
Simply mirroring the dataset would make SplatGPT average, not good. So we curate on purpose: compensating for some biases while introducing others, to nudge the model toward winning patterns.
Addressing Power User Skew
Like most community datasets, stat.ink data suffers from a "long-tail" distribution: a handful of "power users" contribute thousands of matches, while the majority of players upload a few. Splatoon adds a second wrinkle: each match uploaded contains all eight loadouts, so the same high-rank players reappear repeatedly in top level lobbies. If left unaddressed, SplatGPT might overfit to the build preferences of frequently appearing players, rather than truly learning generalized strategies.
To mitigate this issue, we implemented a contribution cap. While stat.ink is anonymized, we developed a coarse discriminator through side-channel analysis to get a probabilistic sense of distinct players, while respecting the site's privacy policy. This discriminator is based on a key insight: the internal JSON representation of gear abilities provided by stat.ink is unsorted and built incrementally. We hypothesized that this data, when combined with the specific weapon ID, could serve as a surprisingly stable and unique fingerprint for a player's particular gear setup for that weapon, even if other players used logically identical abilities. Different players would likely have different internal orderings for the same effective build due to how they acquired or modified their gear. Since gear is expensive to modify, this is surprisingly stable.
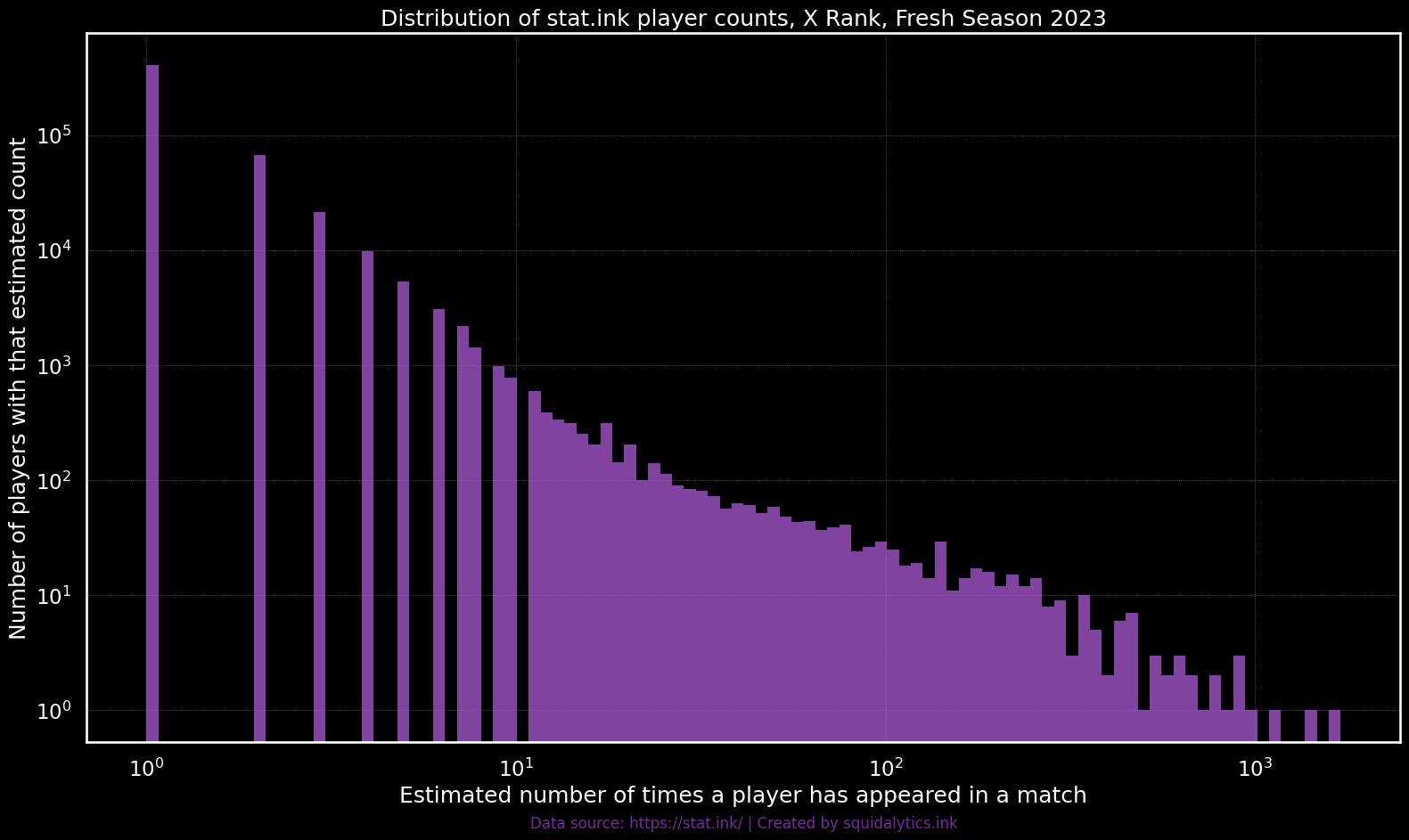
The distribution above, generated using these likely "player fingerprints," starkly illustrates the long-tail phenomenon. The counts of likley-players follow a pattern typical of community contributions when viewed on a log-log scale, confirming the significant skew we aimed to address. Armed with this understanding of the distribution, we used our discriminator to cap likely-player contributions to 100 matches. While this limit is relatively high, it was important to balance value of data from more active (and often higher skilled) players against the risk of the model overfitting to the specific builds of the most active stat.ink users. Full disclosure, this specific number was chosen somewhat arbitrarily but ultimately proved effective.
Learning from Winners
Because SplatGPT's mission is to recommend builds that win, we intentionally biased the training dataset towards successful strategies.
We began by removing all non-competitive modes, leaving only ranked matches. Next, for each weapon, we enforced a 3:2 win-loss ratio (a 60% win rate), based on the rationale weaker builds are more frequently associated with losses. Specifically, for each weapon, we counted victories, calculated how many defeats exceed the target ratio, and randomly dropped those excess losses. This exact ratio was guided by domain expertise (I'm a former competitive Splatoon player), recognizing that tuning this hyperparameter exceeded our available compute capacity. By pruning losing builds, we ensured the training corpus captured strategies that were, on average, significantly more effective.
Staying Relevant: Temporal Filtering and Meta-Awareness
The Splatoon metagame is constantly evolving. Although Nintendo has stopped introducing entirely new weapons, balance patches regularly shift weapon viability as weapons ebb and flow in the meta. Immediately following these updates, players experiment widely, temporarily destabilizing the meta.
To address this, there were two blackouts:
- Two-week blackout after any patch introducing new weapon kits.
- One-week blackout following pure balance patches.
Additionally, we applied a linear undersampling strategy to older data, ensuring the training dataset subtly favored more recent builds and maintained relevance to the current competitive landscape without losing fundamental signal from old matches.
All in all, these filtering steps cut the dataset from the original 120 million builds (15 million matches x 8 builds per match) down to roughly 14 million, an 88% reduction. While this sounds pretty drastic, it's worked remarkably well in practice!
Feeding SplatGPT: Model Training
With our high-quality, strategically-biased training set of around 14 million builds in hand, it was finally time to feed it into SplatGPT and see whether the architecture could learn effectively.
Multilabel Classification
As we saw in Part 2A, builds are naturally represented as sets in Token Space. This means that next-token prediction techniques used by language models aren't really appropriate. Instead, SplatGPT predicts all tokens at once, treating gear completion as a multilabel classification task.
This means that for every possible ability token (e.g., buckets like Quick Respawn 12-14 AP), the model outputs an independent probability of whether that token should appear in the recommended gear set.
From Builds to Training Examples
Since SplatGPT is designed as a gear autocomplete tool, it needs to handle partial build inputs gracefully. Inspired by training methods from large language models, particularly the sliding-window approach for next-token prediction, we used the following technique:
-
Duplicate Entries:
Each complete build is duplicated until we havekcopies, keeping track of each duplicate's index. -
Randomly Drop Tokens:
We randomly generate a list ofkdistinct integers ranging from 1 toN-1(the original sequence length), skewed towards fewer drops. Each duplicated build is assigned one of these integers, indicating how many tokens will be randomly dropped. -
Padding
To keep batches uniform in size during training, partial sets were padded to a fixed length using a special token.
This method provided a diverse set of incomplete builds, training the model to robustly predict missing abilities in a variety of realistic contexts, knowing that the true value is likely a strong build.
Loss Function: Binary Cross-Entropy with Logits
Given the multilabel nature of our task, we chose Binary Cross-Entropy with Logits (BCELogits) as our loss function, treating each token independently. Formally, the model minimizes:
- \( y_i \) = true label (1 if token should be included, 0 otherwise)
- \( z_i \) = model’s predicted logits (raw model outputs before sigmoid)
- \( \sigma(z_i) \) = sigmoid function applied to logits
- \( N \) = total number of possible tokens
BCELogits directly operates on logits, improving numerical stability by combining the sigmoid activation and BCE calculation into a single step. It encourages SplatGPT to confidently assign high logits to correct tokens and push logits of irrelevant tokens toward negative values.
Hardware Setup: Training SplatGPT
Training a model of this complexity required serious computational resources. Early-stage experimentation and rapid prototyping were handled comfortably on my personal machine, an NVIDIA RTX 2080 Ti GPU, which was perfect for quick iterations, debugging, and preliminary testing.
However, for the final production-level training run, I upgraded to a dedicated NVIDIA H100 GPU via a DigitalOcean droplet. This final run took approximately 62 hours of continuous GPU time, a substantial (and frankly risky) investment for a side project. Fortunately, the gamble paid off: the results exceeded my expectations, making the time and resource investment entirely worthwhile.
Emergent Behavior: The <NULL> Token Story
Possibly the most fascinating discovery during training was the unexpected behavior of the special <NULL> token. Initially, the idea behind <NULL> was straightforward: I wanted SplatGPT to generate builds even with no Build Space input, using <NULL> as a placeholder. Early experiments explicitly included <NULL> tokens in the training examples, but this immediately degraded the overall build quality-model performance suffered significantly even when <NULL> wasn’t involved. Worse, occasional inclusion caused severe overfitting whenever the <NULL> token appeared.
On a whim, and driven by a completely baseless hypothesis, I tried something counterintuitive: removing <NULL> entirely from the training data while leaving it as part of the model's vocabulary. Suddenly, <NULL> began to function as a "blank slate" token: when prompted with nothing but <NULL>, the model consistently generated highly effective, weapon-specific builds—even though the model had NEVER explicitly trained on such cases. I was beside myself.
This unexpected behavior was genuinely astonishing. It strongly suggested the model wasn't merely regurgitating memorized training examples; rather, it appeared to be reasoning deeply about gear optimization principles. The <NULL> token demonstrated SplatGPT’s ability to generalize beyond explicitly trained scenarios, indicating true emergent understanding.
This discovery became one of the most compelling insights from the entire training process, significantly boosting my confidence in SplatGPT’s capabilities.
Evaluating SplatGPT's Performance: Results
With training complete, it was finally time to put SplatGPT’s recommendations to the test.
Evaluation Setup
For a quantitative evaluation, I used a specialized dataset generously provided by sendou.ink, a site run by a prominent community member that hosts builds shared by players. The site's owner, Sendou, shared with me builds submitted by verified high-level competitive players, categorized into three tiers. For this evaluation, I'm focusing exclusively on the top-tier, consisting of roughly 30 of the absolute best players in the world at any given time. This is truly the cream of the crop.
While this dataset is completely separate from my original training set, it's important to note it's not exactly a "holdout" set. Because of the significant influence these top players have, many of their builds are likely reflected in the broader player community, indirectly appearing in the filtered training data due to their effectiveness in winning games. Nevertheless, explicitly evaluating against builds directly sourced from top players remains a brutally tough benchmark.
- "Accuracy" here strictly means predicting the exact same build.
- Even when SplatGPT’s predictions differ slightly from these reference builds, the recommendations might still be highly effective and viable in practice.
Both factors mean this evaluation intentionally stacks the deck against SplatGPT.
To rigorously test SplatGPT’s capabilities, I randomly masked between 1 to 8 abilities from each original build (out of the 12 total slots in Build Space). Masking was done directly on build slots, then converted into Token Space for model inference. The scenario with 8 masks is particularly brutal, dropping 66% of the original build information.
Finally, inference was performed using beam search with a width of 5, and results were evaluated in two ways:
- Output (Best of 1): Accuracy (or Hit Rate) using only the top beam candidate, also known as Accuracy@1 or Hit@1.
- Full Beam (Best of 5): Accuracy if the correct build was anywhere within the top 5 candidates, also known as Accuracy@5 or Hit@5.
This methodology is intentionally aligned with standard best practices for evaluating state-of-the-art language models.
Quantitative Results: Exact Hit Rate and Mean Accuracy
Exact Hit Rate
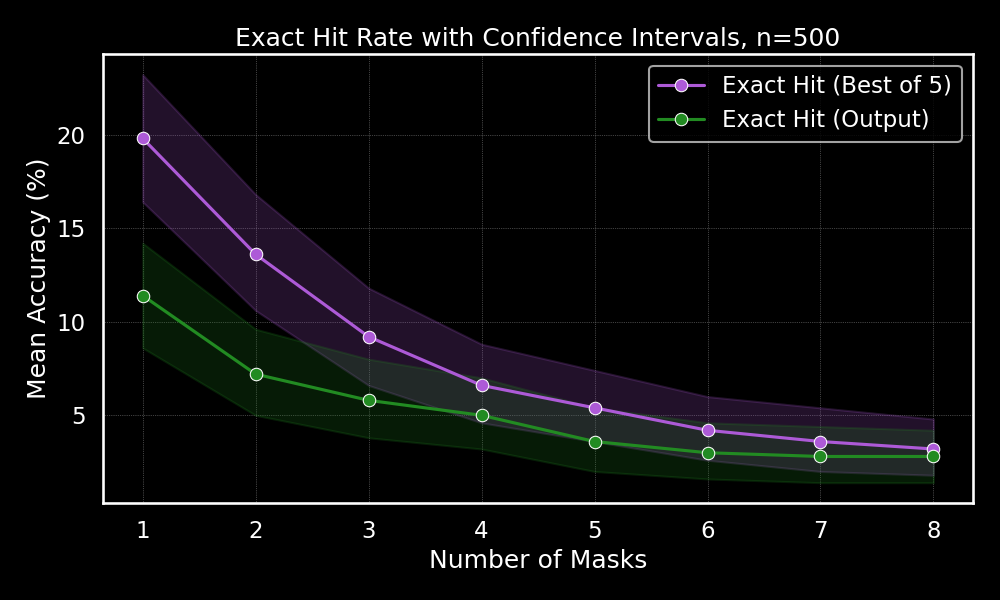
This plot illustrates the percentage of times SplatGPT exactly matched the ground truth builds. As expected, the hit rate drops significantly as more abilities are masked, reflecting the increasing difficulty of the task. While these exact-hit rates may appear low at first glance, they're actually quite impressive given the extreme challenge involved—especially with up to 66% of build information removed. Successfully reconstructing builds exactly under these conditions highlights the model's exceptional ability to capture complex, context-dependent relationships from minimal information.
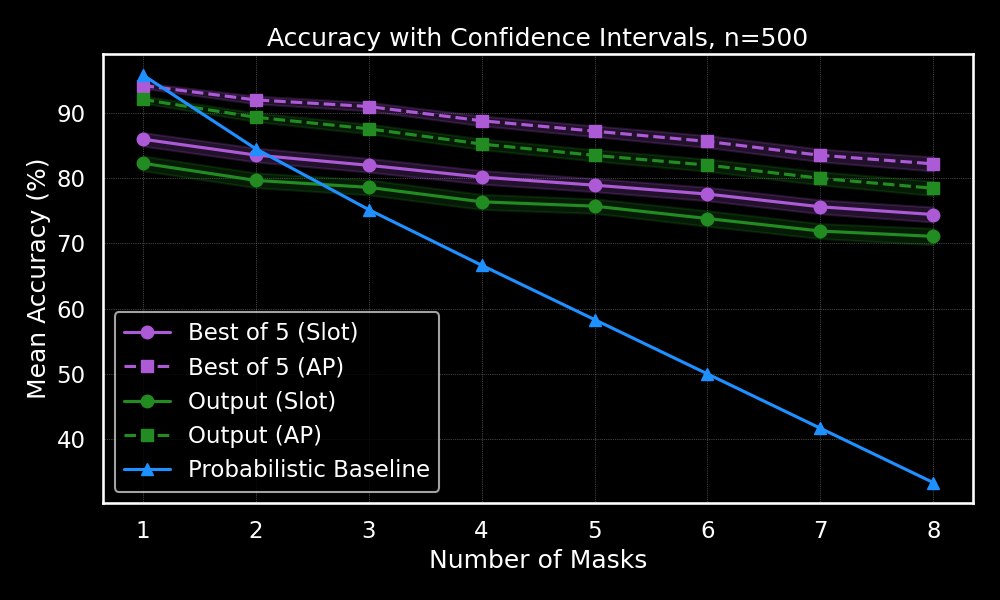
Mean Accuracy
While Exact Hit Rate measures only perfect matches, Mean Accuracy gives a more nuanced perspective on how close SplatGPT's recommendations are. Even if the model doesn't recreate the build exactly, we still want to see how closely it matched the intended strategy. For instance, if the original build has one main slot of Quick Respawn (10 AP) and three subs of Ink Saver (Main) (9 AP), flipping their positions would count as four incorrect slot predictions—even though strategically, these two builds are nearly identical!
The plot clearly shows that SplatGPT maintains impressive accuracy at the AP-level, consistently exceeding 80% accuracy even under severe masking conditions. Slot-level accuracy understandably decreases faster with heavier masking but remains significantly better than random guessing. This shows the model retains a strong grasp of meaningful relationships between abilities and gear slots, even when a majority of the build information is missing.
Together, these metrics demonstrate that while exact matches become increasingly challenging as masking increases, SplatGPT consistently identifies effective, strategically sound builds, successfully capturing the complex nuances essential to gear optimization.
Qualitative Insights: "Inaccuracy" is not "Inferiority"
I hinted at this earlier, but these quantitative accuracy measures have a significant limitation: they're measuring how closely SplatGPT matches a specific set of builds from top players, not necessarily how strong or viable the alternative builds it proposes are. A build that differs from the reference isn't necessarily a "mistake"; often it's just a different yet equally effective strategy.
To illustrate this, let me share a real-world anecdote. For context, the last time I actively played Splatoon competitively was around August 2024, shortly before starting serious work on SplatGPT. Fast-forward to May 2025: while finalizing my beam-search implementation, I noticed something deeply confusing. SplatGPT kept recommending a single sub-slot of Sub Resist Up, a so-called "utility sub" (a strategically chosen ability offering significant value for minimal investment), for the weapon I was most familiar with. This recommendation completely baffled me, because the meta as I remembered it absolutely did not value Sub Resist Up as a utility sub. Convinced this had to be some sort of bug or oversight, I began digging through logs and debugging code. Frustrated, I vented to my co-developer for the splatgpt.ink website about the confusion:

To my amazement, it turned out the confusion wasn't due to a bug at all. Instead, SplatGPT had anticipated a subtle meta shift occurring after my October 2024 data cutoff. The competitive community had gradually rediscovered the strategic value of using Sub Resist Up, specifically due to its interaction with certain high-impact weapons. Although signs of this shift existed as early as October, it hadn't fully taken hold until months later. In other words, SplatGPT had successfully predicted a meta shift, a shift I initially mistook for a bug, simply because the model had identified something strategically valuable before I did.
This realization was genuinely shocking. If the emergence of the <NULL> token behavior hadn't already convinced me, this experience hammered home the idea that SplatGPT isn't just blindly mimicking player strategies, it's genuinely capable of uncovering nuanced, strategically powerful gear optimizations that can even outpace player consensus.
Broader Community Reactions from Top Players
Beyond my own experiences, responses from top competitive players who've tested SplatGPT have been overwhelmingly positive, ranging from impressed surprise to outright disbelief at how effectively the model generates viable, strategic builds. These reactions underscore that the model isn't merely good at recreating known builds but can genuinely capture and even anticipate subtle strategic nuances valued by experienced competitive players.
Practical Impact and Community Deployment (and a Small Lament)
Perhaps most meaningful of all, SplatGPT wasn't merely an academic exercise, it was deployed publicly through the splatgpt.ink website and enjoyed early enthusiastic usage from the community. An API endpoint even collected user feedback, laying groundwork for future improvements via reinforcement learning from human feedback (RLHF) or direct preference optimization (DPO).
Unfortunately, with Nintendo ratcheting up their security on their companion app one more degree, stat.ink suffered a dramatic dropoff in data collection. With the data well dried up, SplatGPT's recommendations inevitably lost their edge as the game's meta moved forward while the model remained frozen in time, stuck forever in October 2024. Understandably, traffic and enthusiasm declined accordingly. Alas, if you choose to build under the Sword of Damocles, you must accept the consequences.
Still, the successful deployment demonstrated SplatGPT's practical potential. The fact that the set completion engine proved so effective strongly suggests it could find similar success elsewhere... perhaps in other complex, noisy optimization domains beyond Splatoon.
For now, though, my focus shifts from deployment back to understanding: I've built a powerful gear-optimizing "brain," but how exactly does it think? In Part 3, I'll dive deep into the interpretability of SplatGPT, leveraging a Sparse Autoencoder (SAE) to map out the surprisingly intricate internal representations of the model.